
How Software Backends Work | Full-Stack Google Contacts Clone with AdonisJs (Node.js) and Quasar Framework (Vue.js)

I'm a full-stack software software with over 8 years experience in various tech fields including Linux server administration, AWS/Azure/Google Cloud cloud architecture, web designs, and software development.
Currently as Senior Backend Engineer at Cavai Advertising.
All software (applications) have some sort of backend for performing sensitive/confidential operations and CPU-intensive tasks which cannot be done on the frontend/client-side of the application. A backend generally refers to a collection of different servers/services running on a machine and made accessible to the frontend/client-side of an application. The word server can refer to different things depending on the context. For example, a machine/computer responsible for providing one form of service or the other is often called a server. While a server can also be an individual software/package installed on a computer (server) and configured to do a particular task (i.e. provide a service). For the purpose of our discussion, let's call the computer itself (whether a laptop, desktop, or dedicated server machine) a server machine to differentiate it from a server application.
A server machine can be any computer capable of running server applications such as your laptop, desktop, or dedicated enterprise servers or virtual cloud servers.
Examples of server applications are:
NGINX web serverused for serving web pages and static files across the internet. A popular alternative is the Apache web server.MySQL database engine (server)used for storing and serving the database of an application. Alternatives are: PostgreSQL, Oracle DB, MSSQL, MongoDB, Apache CouchDB, Cassandra, etc.Redis servercommonly used for providing data caching for applications. Redis is a full-scale database application which can be used for storing databases. There are other usages for Redis such as search and message queues.PHP or Node.js application serverused for performing server-side scripting for applications. These application servers usually sit between the web server (Nginx or Apache) and are responsible for running the software and making calls to the database server, rendering the HTML output and returning the HTML to the web server which then sends the HTML to the client (web broswer / app).Elasticsearch serverused for providing ultra-fast searches through huge datasets.RabbitMQ serverused to provide asynchronous processing of tasks for backends.Postfix mail serverwhich can be installed and configured on your Linux computer for sending and receiving emails instead of sending emails through email providers like Gmail, Mailchimp, etc. Mail servers are difficult to setup and maintain and highly discouraged because of myriads of deliverability issues from self-hosted email servers.
The servers listed above provide dedicated services. A server machine can be configured to run all of these services and even more (if you have sufficient CPU capacity and RAM). These services are able to run on the same server machine because they are often configured to use different ports. Ports are doors through which external users can access different services within a server. Ports are differentiated with port numbers.
Typical Server Applications and their Port Numbers
Examples of port numbers are listed below and also illustrated in the diagram below:
The diagram below illustrates a server with different servers configured to be accessible via ports.
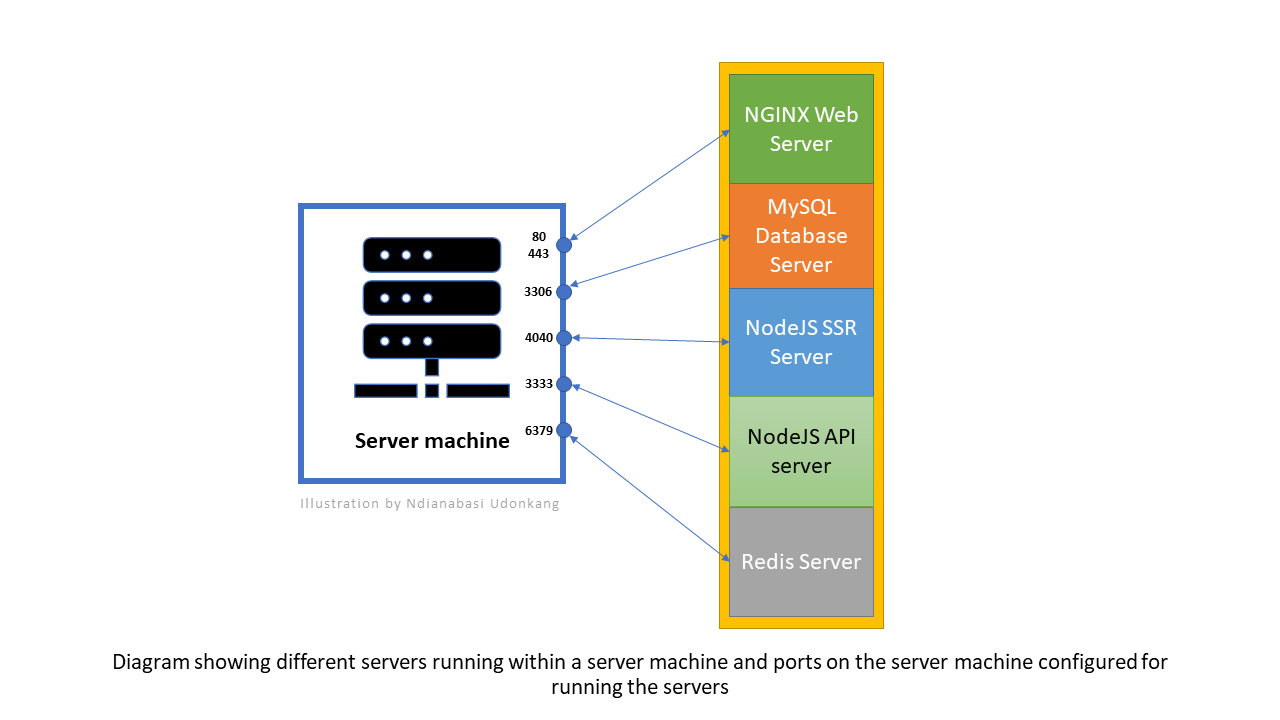
Port
80for websites.80is the default port number for accessing a website hosted by a web server (NGINX). For example, when you enterhttp://www.google.com, the actual address ishttp://www.google.com:80.80is omitted because it is the default port number for the web. It is assumed if not included. However, a web server can be configured to serve a website from a different port such as8080,8000,8111,4040, etc. You are free to configure any number as long as it does not clash with the number number used for anotherserver/servicerunning on the sameserver machine. When you configure non-default port for a website, visitors will only be able to access that website by appending that port . For example:http://www.google.com:8080orhttp://www.google.com:4040, etc.Additionally, port
443is the default port number for secured websites. Secured websites start withhttpsinstead ofhttp. When you enterhttps://www.google.com, the web server (NGINX) will assume that you wanted to access the website via the443port. So the actual address ishttps://www.google.com:443. As a web server administrator, you can configure your secured website to be served from a different port such as4430or4433, etc. as long as it does not clash with an existing port for anotherserver/service.Port
3306is the default port forMySQL database server. So when you want to connect your application (PHP, NodeJS, etc) to theMySQL server, you will typically provide the address127.0.0.1:3306if both application and database server are hosted on the same server machine. Else, you will provide the external IP address of the server machine and the post e.g.https://33.1.22.4:3306, or provide the domain name and port e.ghttps://mysql–instance1.123456789012.us-east-1.rds.amazonaws.com:3306. The domain name will be resolved to the external IP address by the internet's DNS system.A Node.js server responsible for server-side rendering via Vue.js SSR could be configured to run on port
4040. The SSR server will be responsible for rendering HTML pages requested by visitors. If the firewall settings of the server machine is well configured, this port should not exposed to the public and can never be accessed from the outside by a visitor. However, the NGINX web server can be configured tohand overall requests forhttps://demo.akpoho.comtohttp://127.0.0.1:4040. This is calledreverse proxy. In this case, the NGINX web server is acting as areverse proxybetween the SSR server running on port4040and the public internet.In addition to this, the server machine could be running another Node.js server (let's call this the
API server). This API server could be configured by default to run on port3333in the case of theAdonisJS Nodejs server. The API server is responsible for providing the data needed by theSSR serverin order to accurately render the dynamic pages requested by the visitor. The API server is also responsible for processing and storing the data sent from the client. The API server runs the server-side codebase of the application and communicates with the other servers such as the database server, Redis server, Elasticsearch server, RabbitMQ, email server, etc. The API server creates tasks based on the application logic and delegates the tasks to other servers when their help is needed. If the client hydrates into (becomes) a SPA (single page application) after the initial SSR rendering, the API server would be listening for AJAX requests from the frontend as returning data in JSON format to the frontend.A Redis server runs on port
6379by default. In a typical setup, this port should not be accessible from the public if the Redis server and theAPI serverare running on the same server machine. However, theAPI serverhas access to it by calling127.0.0.1:6379.
Typical Lifecycle of a Web Request
Now, let's look at a typical web request on a web application (app.gotedo.com). The lifecycle of the request is depicted in the image below. Each numbered line represent a connection. When a connection is made between any two servers or between the frontend/client of the application and a server, the request and response to that request will pass through that connection.
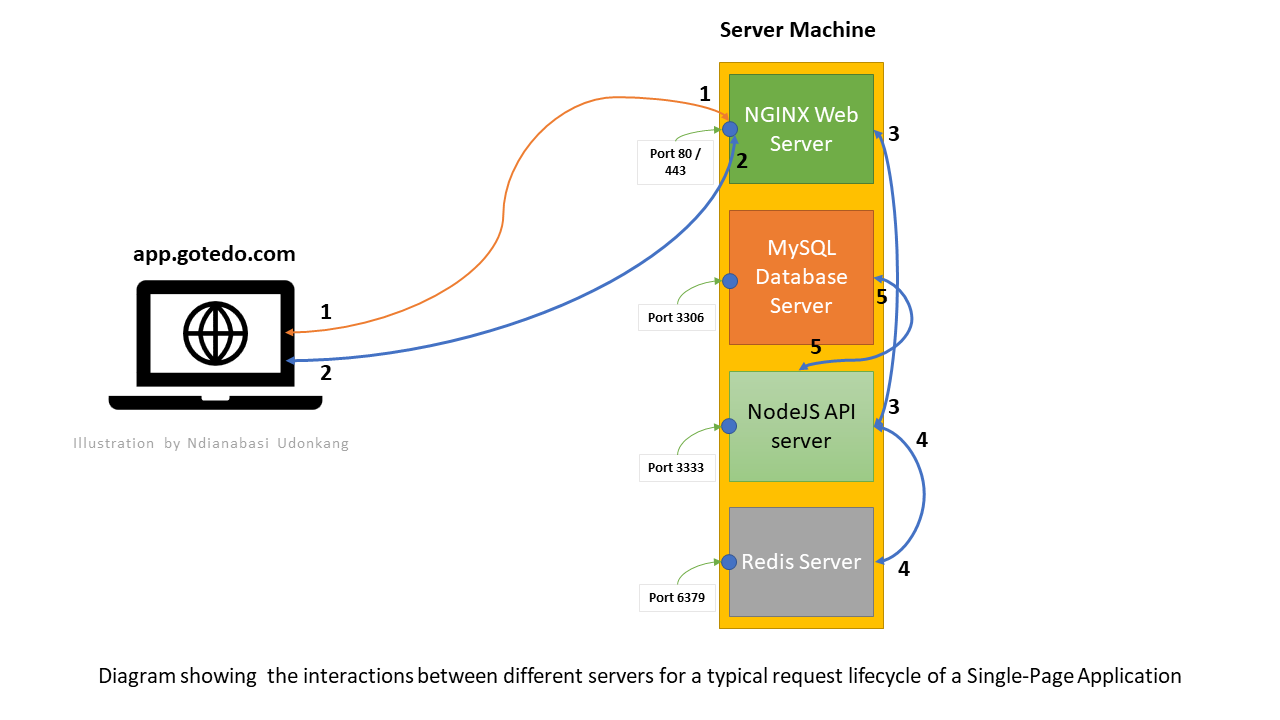
Let's imagine that a user of the Gotedo Church Management Application at app.gotedo.com opens the details page of their church e.g. https://app.gotedo.com/#/organisations/:organisation_id/details.
Since the application is a single-page application (SPA), the frontend will request for the JavaScript chunk for that page. The JavaScript chunk will render into an HTML page on the frontend. This is represented by
connection 1. SPAs typically have only oneindex.html. The rest of the files are.js,.css, and media files. If theindex.htmlfile isn't available, it will be loaded before the JavaScript chunk for that request page is requested. Since they are pre-built static files, the Nginx web server will gladly return the files very quickly. All the requests for these files are made via thehttpsprotocol, so the NGINX web server will intercept them by default since it is configured to run on and listen to requests on port443.In the process of rendering the HTML for the page on the frontend, the browser will encounter a JavaScript API call for the details of the church. The API call could be made to the address:
https://api.gotedo.com/v1/organisations/:organisation_id. When this request is made, it will first arrive at the NGINX web server because thehttpsprotocol resolves to port443by default and NGINX is configured to listen to that port. This interaction between the frontend and NGINX for the API call is represented byconnection 2.The
NGINX serverhas been configured to forward all requests forhttps://api.gotedo.com/v1/to a privateAdonisJS (Node.js) API serverrunning on port3333. So when the above request arrives NGINX, it quickly hands over the request to the API server and then listens for a response from the API server on the same connection. This is represented byconnection 3. TheAPI serverchecks its routing configuration and determines which controller and controller function to call in order to get the requested information. When it calls that function, the function makes a request to either theMySQL database serveror theRedis serverin order to get the information about that church.If the function implements a call to Redis cache for the cached data of the church, the
API serverwill call theRedis serverfor the information by specifying the index where the cached data is store. If found, theRedis serverwill return the data back to theAPI server. This is represented byconnection 4In the case where a Redis cache was not implemented in the controller function or the Redis server did not find the requested index, the
API serverwill call theMySQL database serverand request for the information of the church and return same to theAPI server. This is represented byconnection 5.
Once the API server has the requested information about the church, it will format it JSON data and return the JSON data via the established connection 3 to the NGINX web server. The NGINX web server will then return the JSON data to the frontend via connection 2. The browser then combines the JSON data with the HTML for that page to render the details page for the church.
This is typically how all application works. Most SPA work like this. This setup was simplified as some complex application could have more servers running on the server machine for more tasks.
Aside from storing and fetch application data, a software backend could be setup to provide more services such as:
Processing and storing of media files (images and videos) uploaded by users. These media files could be stored locally on the server machine to uploaded to another service such as Amazon S3 for storage. During processing of images, different image dimensions could be generated from the uploaded image. The image quality can also be optimised to reduce its size. The same with video files where the backend can be setup to generate video files at different resolutions.
Sending of realtime and periodic push, email, and SMS notifications to users when certain events occur within their contexts. Periodic notifications can be setup with server cron jobs.
Periodic backup of the database using cron jobs.
Deep analysis of user data to better understand how the application is used and how to improve the application.
Serverless Backends
The advent of cloud services has also introduced the concepts of serverless backends. Serverless backends simple means a strategy of outsourcing some of the tasks you should have configured on your own server machine to another server machine completely owned by another company.
For example, instead of installing the sharp library on your server machine and then writing tons of code to handle image and video processing within your API server, you could open an account with cloudinary, get an API key for account, and then directly upload images and video from the browser into the cloudinary server for progressing and storage. When processed and stored, your frontend will fetch images from cloudinary instead your server machine. In this case, cloudinary is your serverless backend for image and video processing.
The same strategy can be used for other services such as email, SMS, and push notifications.
There are also cloud or lambda functions which you can setup on various cloud providers. These functions can be called remotely from your API server and they will run tasks they have been programmed to do. Cloud and lambda functions can be used to perform most tasks done on the backend.
I hope you have learnt how backends for software/application work. This is the same for any programming language. The difference will be in the API server which will be written in the language of the main programming language.
See you in the next lesson where we will setup our backend by installing some server applications.



